
Managing datasets
You can manage the datasets included in Landing, Storage, Transform, Data mart, and Replication data tasks to create transformations, filter the data, and add columns.
The included datasets are listed under Datasets in the Design view. You can select which columns to display with the column picker (![]() ).
).
Datasets in the Design view of a data task

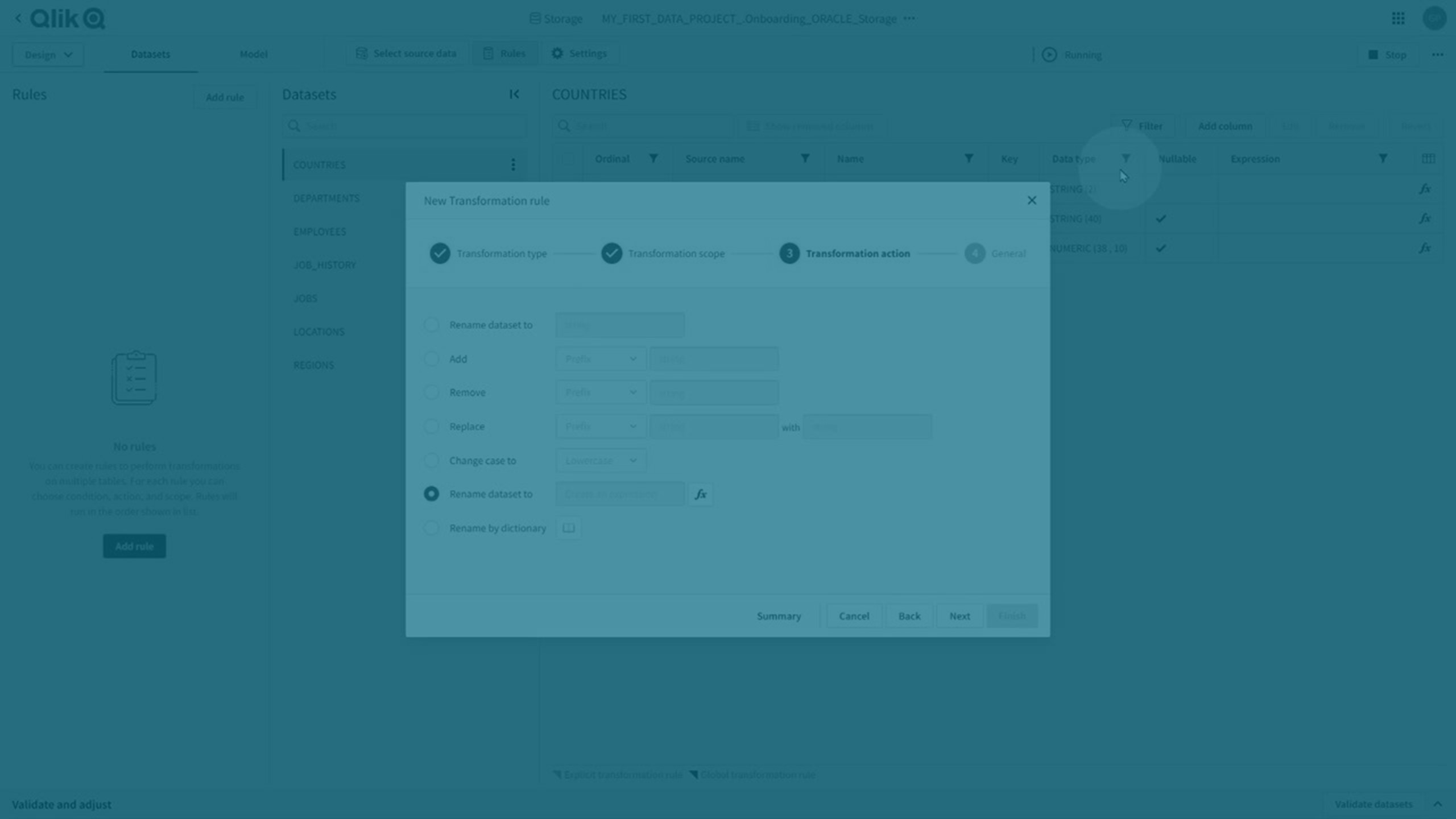
Transformation rules and explicit transformations
You can perform both global and explicit transformations .
Transformation rules
You can perform global transformations by creating a transformation rule that uses % as a wild card in the scope to apply to all matching datasets.
-
Click Rules, and then Add rule to create a new transformation rule.
For more information, see Creating rules to transform datasets.
Transformation rules are indicated by a dark purple corner on the affected attribute.
Explicit transformations
Explicit transformations are created:
-
When you use Edit to change a column attribute
-
When you use Rename on a dataset.
-
When you add a column.
Explicit transformations override global transformations, and are indicated by a light purple corner on the affected attribute.
Dataset models
Datasets can be either source-based or target-based, depending on the task type and the operations in the task. The dataset model used affects the behavior of the pipeline at source changes, and which operations you can perform.
-
Source-based datasets
The dataset is based on source datasets and will only hold changes in metadata. A change in source data is automatically applied which may cause changes in all downstream tasks. It is not possible to change column order, or changing source dataset.
The following task types always use a source-based dataset model: Landing, Storage, Registered data, Replication, and Landing in a data lake.
-
Target-based datasets
The dataset is based on the target metadata. If a column is added from the source, or removed, it is not automatically applied to the next downstream task. You can change column order, and change the source dataset. This means the task is more self-contained, and lets you control the effect of source changes.
The following task types can use a target-based dataset model: Transform, Data mart. There are some cases where a source-based model is used for Transform tasks based on the operation.
-
If a SQL transformation or a transformation flow performs a column selection, the dataset will be target-based. For example, if you use SELECT A, B, C from XYZ in a SQL transformation, or use the Select columns processor in a transformation flow.
-
If the default columns are maintained, the dataset is source-based. For example, if you use SELECT * from XYZ in a SQL transformation.
-
Updating projects from a source-based model to a target-based model
Existing projects are updated to the target-based dataset model when applicable. You will be guided through the update process when first opening a project. There are some considerations when importing and exporting projects with different dataset models.
-
It is not possible to import a project with a source-based model to a project with a target-based model.
Import the project with a source-based model to a new project, update the new project, and then export the resulting project. You can now re-import this project to the project with a target-based model.
-
It is not possible to import a project with a target-based model to a project with a source-based model.
Update the project to a target-based model before importing a project with a target-based model.
Filtering a dataset
You can filter data to create a subset of rows, if required.
-
Click Filter.
For more information, see Filtering a dataset.
Renaming a dataset
You can rename a dataset.
-
Click
 on a dataset, and then Edit.
on a dataset, and then Edit.
Adding columns
You can add columns with row-level transformations, if required.
-
Click Add column
For more information, see Adding columns to a dataset.
Editing a column
You can edit column properties by selecting a column and clicking Edit.
-
Name
-
Key
Set a column to be a primary key. You can also set keys by selecting or deselecting in the Key column.
-
Nullable
-
Data type
Set the data type of the column. For some data types, you can set an additional property, for example, Length.
Information noteWhen you change the data type or the data type size of a column, this may have implications on the tasks using the dataset. For more information, see Managing data types.
Removing columns
You can remove one or more columns from a dataset.
-
Select the columns to remove, and click Remove.
If you want to see removed columns, click Show removed columns. Removed columns are indicated with strike-through text. You can retrieve a removed column by selecting it, and clicking Revert.
Reverting explicit changes to columns
You can revert all explicit changes to one or more columns.
-
Select the columns to revert changes to, and click Revert.
Changes from global transformation rules will not be reverted.
If you revert an added column, it will be removed.
Dataset settings
You can change settings for the dataset. The default setting is to inherit the setting of the data task, but you can also change a setting to be explicitly On or Off.
-
Click
 on a dataset, and then Settings.
on a dataset, and then Settings.
Viewing data
You can view a sample of the data to see and validate the shape of your data as you are designing your data pipeline.
The following requirements must be met:
-
Viewing data is enabled on tenant level in the Administration activity center.
To enable it, go to the Settings page, select the Feature control tab, and turn on Viewing data in Data Integration.
-
You are assigned the Can view data role in the space where the connection resides.
-
You are assigned the Can view role in the space where the project resides.
To view sample data in Datasets tab in the Design view.:
-
Click View data in Physical objects.
A sample of the data is displayed. You can set how many data rows to include in the sample with Number of rows.
To change between datasets and tables:
-
Select Datasets to view the logical representation of the data.
-
Select Physical objects to view the physical representation in the database as tables and views.
News noteThis option is not available if the physical representation is not yet created.
You can filter the sample data in two ways:
-
Use
 to filter which sample data to retrieve.
to filter which sample data to retrieve.For example, if you use the filter ${OrderYear}>2023 and Number of rows is set to 10, you will get a sample of 10 orders from 2024.
-
Filter the sample data by a specific column.
This will only affect the existing sample data. If you used
to only include orders from 2024, and set the column filter to show orders from 2022, the result is an empty sample.
You can also sort the data sample by a specific column. Sorting will only affect the existing sample data. If you used ![]() to only include orders from 2024 and invert the sort order, the sample data will still only contain orders from 2024.
to only include orders from 2024 and invert the sort order, the sample data will still only contain orders from 2024.
You can hide columns in the data view:
-
Hide a single column by clicking
on the column, and then Hide column. -
Hide several columns by clicking
on any column, and then Display columns. This lets you control visibility for all columns in the view.
Validating and adjusting the datasets
You can validate all datasets that are included in the data task.
Expand Validate and adjust to see all validation errors and design changes.
Validating the datasets
-
Click Validate datasets to validate the datasets.
Validation includes checking that:
-
All tables have a primary key
-
There are no missing attributes.
-
There are no duplicate table or column names.
You will also get a list of design changes compared to the source:
-
Added tables and columns
-
Dropped tables and columns
-
Renamed tables and columns
-
Changed primary keys and data types
Expand Validate and adjust to see all validation errors and design changes.
-
Fix the validation errors, and then validate the data sets again.
-
Most design changes can be adjusted automatically, except changed primary keys or data types. In this case, you need to sync the datasets.
Preparing the datasets
You can prepare datasets to adjust design changes with no data loss if possible. If there are design changes that cannot be adjusted without data loss, you will get the option to recreate tables from source with data loss.
This requires stopping the task.
-
Click
 , then Prepare.
, then Prepare.
When the datasets are prepared, validate the datasets before restarting the storage task.
Recreating datasets
You can recreate the datasets from the source. When you recreate a dataset, there will be data loss. As long as you have the source data, you can reload it from the source.
This requires stopping the task.
-
Click
, then Recreate tables.
Limitations
-
In Google BigQuery, if you delete or rename a column, this will recreate the table and lead to data loss.