
Creating and managing data marts
Once you have onboarded your data, you can then create data marts using the data from the Storage or Transform tasks. You can create any number of data marts depending on your business needs. Ideally, your data marts should contain repositories of summarized data collected for analysis on a specific section or unit within an organization, for example, the Sales department.
In addition to storing tables in the data warehouse, you can also store tables as Iceberg tables that are managed by the data platform. This option is currently only available with Snowflake projects. This is possible by selecting Snowflake-managed Iceberg tables under Table type in the task settings.
Prerequisites
You can use data tasks of the following types as source for a data mart:
-
Storage
-
Transform
Before you can create a data mart, you need to do the following in the source data tasks:
- Populate the datasets with data that you want to use in your data mart. For more information, see Onboarding data to a data warehouse.
-
Create a dataset relational model to define the relationships between the source datasets. For more information, see Creating a data model.
Warning noteAll source datasets must have keys.
Creating a data mart
To create a data mart:
-
Open your project.
-
Do one of the following:
- Click Create in the top right and select Create data mart.
-
In the source data task, click
 in the bottom right corner and then select Create data mart.
in the bottom right corner and then select Create data mart.
The Create data mart dialog opens.
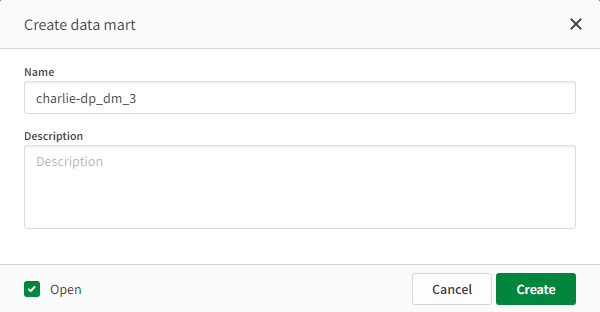
-
Provide a name for your data mart and, optionally, provide a description as well.
-
If you want to configure the data mart later, clear the Open check box and then click Create. Otherwise, just click Create.
The Data mart opens on the Data mart tab.

- Select your source data as described in Selecting your source data
- If you want the data mart to contain dimensions, add dimensions as described in Adding dimensions and a fact to the data mart
- If you want the data mart to contain a fact, add a fact as described in Adding a fact
- If the data mart contains both dimensions and a fact, add the dimensions to your star schema as described in Building a star schema
- Create the datasets in your data mart and populate them with data as described in Populating your data mart
Learn more
Selecting your source data
You select your source data from the datasets in the source data task.
To do this:
-
Click the Select source data button in the middle of the tab or click the Select source data toolbar button.
The Select source data dialog opens.
-
From the Projects drop-down list, select which project to get source data from.
You can add datasets from the current project, or from another project. To add datasets from another project:
-
You must have at least Can consume role in the space of the consumed project.
-
Both projects must be on the same data platform.
For more information about cross-project pipelines, see Building cross-project pipelines .
-
-
From the Data tasks drop-down list, select a Storage task, or a Transform task if you created transformations.
-
Either leave the default % to search for all datasets or enter the name of a specific dataset to find. Then click Search.
-
Select the desired datasets and then click Add selected tables.
-
Click OK to close the dialog and then proceed to Add a fact and/or Add dimensions.
Adding dimensions and a fact to the data mart
Once you have selected you source data, you can then proceed to build your data mart. A data mart can have a fact dataset, dimensions datasets, or a combination of both (where the dimension datasets are logically related to the fact dataset).
Adding dimensions
To add a dimension.
-
Click the Add dimension button.
The Add dimension dialog opens.
-
The following settings are available:
- Most granular dataset: Select a dataset.
- Name: Specify a display name for the dimension. The default is the most granular dataset name.
- Description: Optionally, provide a description.
- History type: Select one of the following:
- Type 1: The existing record in the dimension will be updated whenever the corresponding record in the Storage is updated.
- Type 2: A new record will be added to the dimension whenever the corresponding record in the Storage is updated.
-
Related dataset to denormalize: Any datasets that can be denormalized in the dimension dataset (according to the relationships in the source data asset model) will be available for selection here.
Example of a dimension that can be denormalized 
-
Click OK to save your settings.
The dimension will be added to the Dimensions list on the left.
See also Role-playing dimensions.
Viewing information about a dimension
When you select a dimension, the Source relational model tab will be shown in the center pane. This tab shows the source datasets that are consolidated in the dimension. Datasets that you chose to denormalize when you added the dimension will be shown selected (and grayed out).

Adding a fact
To add a fact:
-
Click the Add fact button.
The Add fact dialog opens.
-
The following settings are available:
- Fact: Select a dataset to be the fact. The dataset should define the granularity of the fact you are creating.
- Name: Specify a display name for the fact. The default is the fact name.
- Description: Optionally, provide a description.
- Related datasets to denormalize: Any datasets that can be denormalized in your fact dataset will be available for selection here.
- Advanced
- Use current data: When selected (the default), the fact will not contain a transaction date column.
-
Choose transaction date: To locate data according to a specific transaction date, select this option and then select a date column. This is useful if your star schema contains type 2 dimensions and you need to find the correct data for a specific transaction. For example, if a customer has multiple addresses, it might be possible to find the correct address according to the order date.
Example use case:
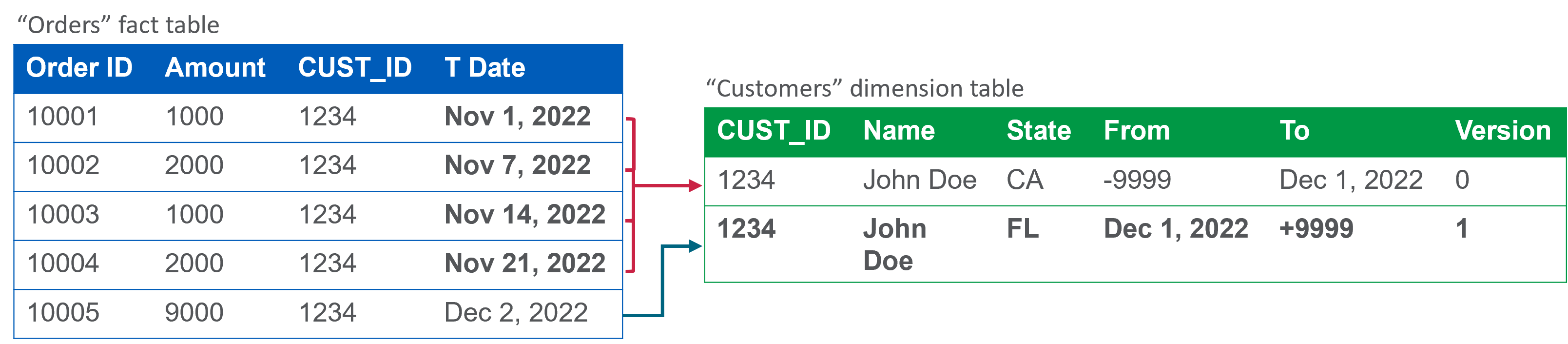
A retailer needs to create a data mart to analyze the relationship between orders and customers. The data mart should be able to answer queries such as: Which US state had the highest sum of orders in Q4 2022?
If the retailer selects the Use current data option, only the most current record version in the Customers table will be included in the calculation.
Ignoring the transaction date will result in inaccurate data as illustrated below:

If the retailer selects the Choose transaction date option, however, the customer's orders will be associated with the correct record version in the Customers table.
This will allow the retailer to accurately calculate the total sum of orders per state in Q4 2022.
 Tip noteNote that the transaction date can be leveraged differently in each data mart, according to business needs. For example, in one data mart it could be used to analyze order dates, while in another data mart it could be used to analyze shipping dates.
Tip noteNote that the transaction date can be leveraged differently in each data mart, according to business needs. For example, in one data mart it could be used to analyze order dates, while in another data mart it could be used to analyze shipping dates.
-
Click OK to save your settings.
The fact will be added to the Facts list on the left.
Viewing information about the fact
When you select a fact, the following tabs are shown in the center pane:
- Star schema model (default): Shows a graphical representation of the dataset relationships within the data mart.
-
Fact model: Shows any datasets related to the fact dataset. Datasets that you chose to denormalize when you added the fact will be shown selected (and grayed out).
Orders Details fact with a denormalized Orders dataset 
- Transaction date: The name of the transaction column if you selected the Choose transaction date option when adding the fact.
Unknown and late-arriving dimension handling
Every dimension contains -1 and 0 rows, which are the dimension’s business key (object ID). Row -1 is reserved for late-arriving dimensions, while 0 is reserved for unknown dimensions.
Unknown dimensions
“Unknown” is data that was unavailable when the dimension was originally created. For example, let’s say you have an ORDER fact with a SHIPPER column that is the business key for the SHIPPER dimension. If the ORDER fact row has not been shipped yet - and thus has NULL for the SHIPPER column - it will become related to the 0 record (which denotes an Unknown for the dimension). When the ORDER fact is later updated with a SHIPPER value (for example, USPS), the related dimension ID (0) will be updated in turn.
Late-arriving dimensions
A late-arriving dimension has a key which exists in the new fact data, but which does not yet exist in the dimension. For example, if the SHIPPER in the ORDER fact has a value of "NEWSHIP" for a new shipper and that business key does not yet exist in the DIM_SHIPPER dimension, the data mart processing will relate that fact to the -1 row. This denotes a missing dimension member in your dimension table. When the "NEWSHIP" business key arrives for the DIM_SHIPPER dimension, its dimension row will be created, and the fact record updated to align with the previously missing dimension.
Building a star schema
Once you have added dimensions to your data mart, you can then proceed to connect them to your fact dataset, thereby creating a star schema.
To do this:
- Select your fact in the Facts list on the left.
-
Select which dimensions to add from the Recommended dimensions list on the right.
Recommended dimensions are shown connected to the fact dataset with a dotted line.
In the image below, some of the dimensions were added earlier and are therefore connected with a solid gray line.
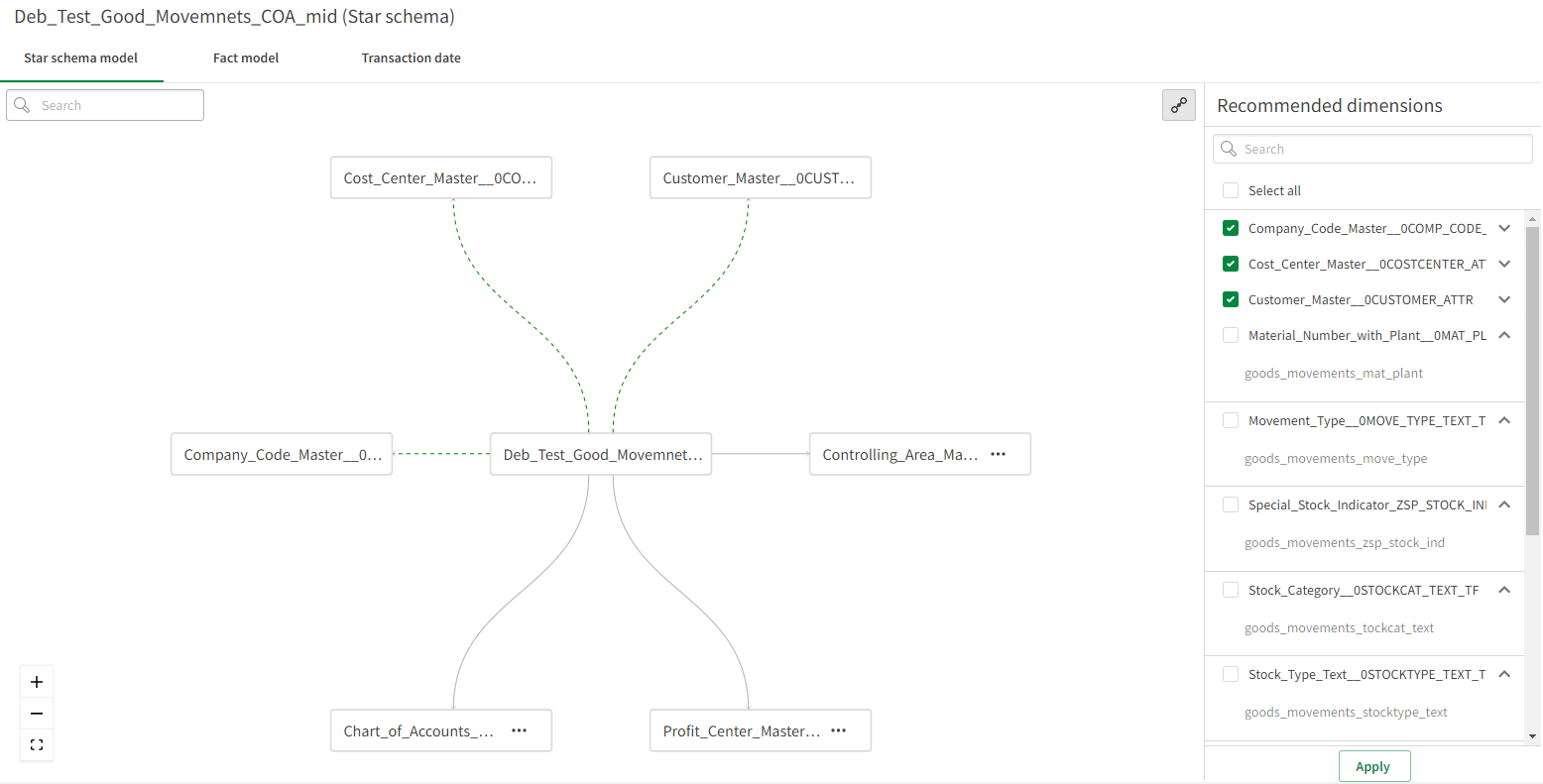
-
Click Apply to add the dimensions.
The dimensions will be shown connected to the fact dataset with a solid gray line.
-
To close the Recommended dimensions panel, click
 .
.
Populating your data mart
Once you have designed your data mart, you can then proceed to populate it.
To do this:
-
Click the Prepare toolbar button in the top right.
The preparation process includes creating datasets and views in the data mart, and updating the Catalog.
You can follow the progress under Preparation progress in the lower part of the screen.
After the preparation is complete, the Prepare button changes to Run.
-
Optionally, validate the data mart as described in Validating and synchronizing your data mart below.
-
Click the Run button.
The window switches to Monitor view, showing the loading progress and status of the datasets in your data mart.

Every source record will be processed by the data mart, even deleted records. This is done to ensure that historical information is kept.
Validating and synchronizing your data mart
Validating the data mart ensures that the data mart metadata is identical to the corresponding metadata in the Storage (or Transform if defined). Validating the data mart also compares the created metadata against the current star schema design. For example, if you run the validation after adding a dimension to an already created data mart, the validation will fail.
To validate the data mart:
-
Either select Validate datasets from the
menu to the right of the Run button or click the Validate datasets button at the bottom right of the window.A Validation is completed message will be shown.
-
If the metadata is not in sync or if there are star schema design conflicts, the Validate and adjust pane at the bottom of the window will automatically open with the validation report.
Example of a data mart with a star schema design conflict: 
Example of a data mart with validation errors:

-
To resolve any Pending design changes issues, click the
button in the top right and select Prepare. If the value of the Can be altered without data loss column is Yes, an ALTER operation will be performed. Otherwise, the data mart tables will be recreated.Note that all Validation errors need to be resolved manually.
Managing data marts
This section describes the various options available for managing your datasets and data marts.
Refining facts or dimensions
In the Datasets tab, you can perform various operations to refine your facts and dimensions such as creating transformation rules (for instance, replacing columns values), and adding column-level expressions. The Datasets tab is located to the right of the Data mart tab:
Adding rules
For an explanation of how to add global rules, see Creating rules to transform datasets
Adding new columns
You can add new columns to the target dataset.
-
Adding a new column from scratch
Click + Add.
Provide a name for the column, and set an expression to define the column data.
For more information, see Adding columns to a dataset.
-
Adding a column from source
Click
 next to Add and select Add column from source.
next to Add and select Add column from source.Select a column from the source dataset.
Reordering columns
You can change the ordinal position of a column.
-
Select a column.
-
Click
 and then Reorder.
and then Reorder. -
Use the arrows to move the column up or down.
-
Close Change ordinal when you are ready.
Role-playing dimensions
A role-playing dimension is the same dimension used multiple times within the same star schema, but with different meanings. This is commonly seen with the Date and Customer dimensions. For example, your star schema might have two Date entities, one representing the Order Date and the other representing the Received Date.
To add or edit a dimension's role name:
- Click the icon in the dimension node and select Edit dimension name in this star schema.
-
In the Edit dimension name in this star schema dialog, enter a name (or edit the existing name) in the Dimension name in this star schema field and click OK.
The new name will appear below the original dimension name.
Additional management options
The following table describes additional management options:
| To | Do this |
|---|---|
| Add additional source datasets | See Selecting your source data. |
| Add additional facts | See Adding a fact |
| Add additional dimensions | See Adding dimensions and a fact to the data mart. |
| Delete a dimension | Select the dimension in the Dimensions pane, and then select Delete from the |
| Delete a fact | Select the fact in the Facts pane, and then select Delete from the |
| Recreate a data mart |
Click the Information noteIf there are problems with individual tables, it is recommended to first try reloading the tables instead of recreating them. Recreating tables may cause a loss of historical data. If there are breaking changes, you must also prepare downstream data tasks that consume the recreated data tasks to reload the data.
|
| Stop a running data mart task | Click the Stop button in the top right. |
| Prepare a data mart task |
Click the
You can follow the progress under Preparation progress in the lower part of the screen. Information noteBefore you prepare a task, stop all tasks that are directly downstream.
|
Scheduling a data mart task
You can schedule a data mart task to be updated periodically. You can set a time based schedule, or set the task to run when input data tasks have completed running.
Click ... on a data task and select Scheduling to create a schedule. The default scheduling setting is inherited from the settings in the project. For more information about default settings, see Data mart default values.
You need to set Scheduling to On to enable the schedule.
Time based schedules
You can use a time based schedule to run the task regardless of when the different input sources are updated.
-
Select At specific time in Run the data task.
You can set an hourly, daily, weekly or monthly schedule.
Event based schedules
You can use an event based schedule to run the task when input data tasks have completed running.
-
Select On specific event in Run the data task.
You can select if you want to run the task when any of the input tasks have completed successfully, or when any of a selection of input tasks have completed successfully.
Reloading data
You can perform a manual reload of data. This is useful when there are issues with one or more tables.
-
Open the data task and select the Monitor tab.
-
Select the tables that you want to reload.
When a dimension is selected for reload, all facts that use that dimension will also be reloaded to maintain integrity.
-
Click Reload tables.
You can cancel the reload for tables that are pending reload by clicking Cancel reload. This will not affect tables that are already reloaded, and reloads that are currently running will be completed.
The reload is performed by:
-
Truncating the selected dimensions and facts.
-
Loading the selected dimension tables from the upstream data task.
-
Loading the fact tables from the upstream data task. This includes:
-
Explicitly selected fact tables.
-
Fact tables that are related to a dimension that is reloaded.
-
Data mart settings
Click the Settings toolbar button to open the Settings: <data-mart-name> dialog.
General settings
In the General tab, the following settings are available:
- Database: The database in which the data mart will be created
- Data task schema: The schema in which the datasets will be created
- Internal schema: The schema in which the internal datasets will be created
-
Default capitalization of schema name
You can set the default capitalization for all schema names. If your database is configured to force capitalization, this option will not have effect.
- Prefix for all tables and views
You can set a prefix for all tables and views created with this task.
Information noteYou must use a unique prefix when you want to use a database schema in several data tasks.
Runtime settings
In the Runtime tab, the following settings are available:
- Parallel execution: Enter the maximum number of database connections that Qlik Cloud is allowed to open for the task. The default number is 10.
- Warehouse: Only relevant for Snowflake. The name of the Snowflake data warehouse.
Catalog settings
-
Publish to catalog
Select this option to publish this version of the data to Catalog as a dataset. The Catalog content will be updated the next time you prepare this task.
For more information about Catalog, see Understanding your data with catalog tools.
View type settings
The View type settings are only applicable for Snowflake.
-
Standard views
Use Standard views for most cases.
-
Snowflake secure views
Use Snowflake secure views for views designated for data privacy or sensitive information protection, such as views created to limit access to sensitive data that should not be exposed to all users of the underlying tables.
Information note Snowflake secure views can execute more slowly than Standard views.
Table type settings
These settings are only available in projects with Snowflake as data platform.
-
Table type
You can select which table type to use:
-
Snowflake tables
-
Snowflake-managed Iceberg tables
You must set the default name of the external volume in Snowflake external volume.
-
-
Cloud storage folder to use
Select which folder to use when landing data to the staging area.
-
Default folder
This creates a folder with the default name: <project name>/<data task name>.
-
Root folder
Store data in the root folder of the storage.
-
Folder
Specify a folder name to use.
-
-
Sync with Snowflake Open Catalog
Enable this to let Snowflake Open Catalog manage the files in cloud file storage.
Limitations
There are limitations when you use source datasets matching all these conditions:
-
Created by SQL transformation or a transformation flow
-
Non-materialized
-
Historical Data Store (Type 2) turned off
These datasets are considered updated on every run which may affect efficiency and cost. You can mitigate this by:
-
Changing the source datasets to be materialized.
-
Using explicit dataset transformations.
-
Creating global rules that transform multiple datasets.
Relationships
-
It is not possible to relate data from two datasets. Create a transform task where you define the relationship in the data model, and use the transform task as source for the task.
-
When two datasets are related in the data model, both datasets will be available in the task, even if you only selected one of the datasets.